
Big Data ist eine umfangreiche Sammlung von Daten, die aufgrund ihrer Größe und Komplexität spezielle Verarbeitungsmethoden erfordert. Diese Daten werden oft als das neue Gold des 21. Jahrhunderts betrachtet, da ihre effektive Nutzung entscheidend für den Unternehmenserfolg ist.
Die Verarbeitung von Big Data stellt jedoch eine komplexe Herausforderung dar, die nicht nur spezialisierte Kenntnisse, sondern auch den Einsatz moderner Technologien erfordert.
Technologien wie Machine Learning und Grid Computing gewinnen zunehmend an Bedeutung, um Unternehmen bei der Analyse und effektiven Nutzung dieser großen Datenmengen zu unterstützen. Der Einsatz dieser fortschrittlichen IT-Lösungen hilft, die stetig wachsenden Anforderungen an die Datenverarbeitung zu meistern und trägt maßgeblich zum Unternehmenserfolg bei.
Definition: Was ist Big Data
Big Data bezeichnet umfangreiche Datenkollektionen, die aufgrund ihrer Größe, Vielfalt und schnellen Generierung besondere Herausforderungen an die Verarbeitung stellen. Diese Datenmengen sind häufig unstrukturiert oder semi-strukturiert und stammen aus verschiedensten Quellen wie Webaktivitäten, Sensoren oder multimedialen Inhalten.
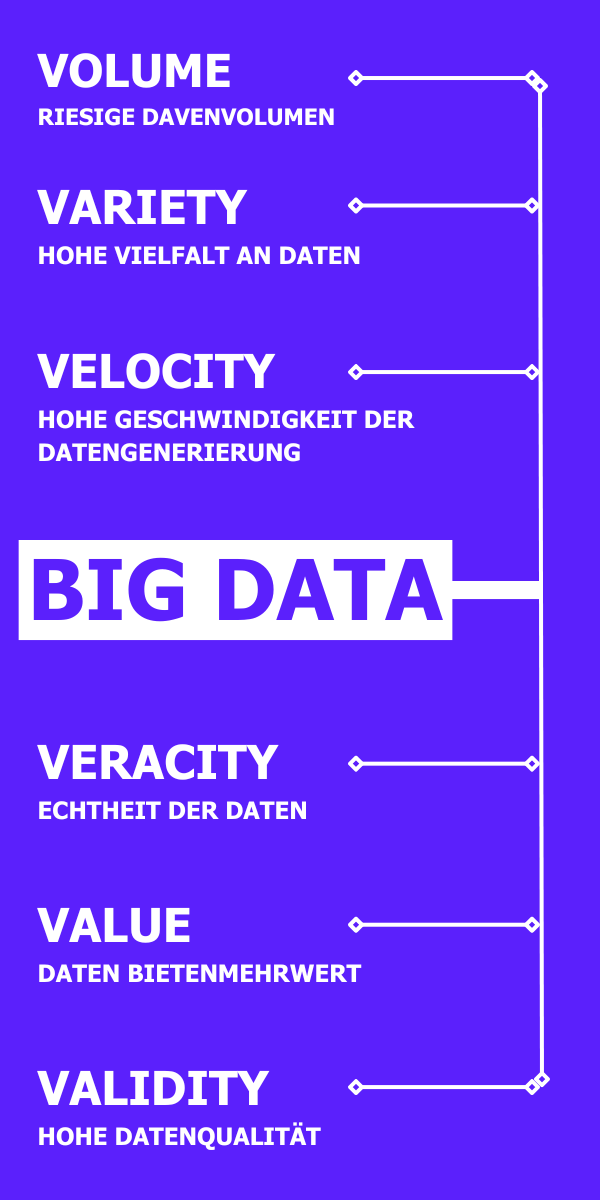
Die charakteristischen Schlüsseldimensionen von Big Data sind:
- Volumen (Volume): Das immense Datenvolumen, das verarbeitet und gespeichert werden muss.
- Vielfalt (Variety): Die unterschiedlichen Datenquellen und -typen, die analysiert werden.
- Geschwindigkeit (Velocity): Die hohe Geschwindigkeit, mit der die Daten erzeugt und verarbeitet werden müssen.
- Werthaltigkeit (Value): Der Mehrwert, den die Daten für das Unternehmen generieren.
- Validität (Validity): Die Zuverlässigkeit und Genauigkeit der Daten.
Die Analyse von Big Data erfordert fortschrittliche Technologien wie Hadoop oder Apache Spark, die es ermöglichen, diese Informationen effizient zu verarbeiten und dadurch strategische Vorteile zu erzielen. Big Data ist somit nicht nur ein technisches Phänomen, sondern auch ein entscheidender wirtschaftlicher Faktor, der neue Geschäftsmodelle und Wettbewerbsvorteile ermöglicht.
Anwendungsberiche: Beispiele wie Big Data die Welt verändert
Hier ist unsere ausführlichere Tabelle, die die praktischen Anwendungen von Big Data in verschiedenen Sektoren zusammenfasst. Diese Beispiele illustrieren den erheblichen Einfluss von Big Data auf diverse Bereiche und dessen Beitrag zur Lösung globaler Herausforderungen.
Hier ist eine ausführlichere Tabelle, die die praktischen Anwendungen von Big Data in verschiedenen Sektoren zusammenfasst. Diese Beispiele illustrieren den erheblichen Einfluss von Big Data auf diverse Bereiche und dessen Beitrag zur Lösung globaler Herausforderungen.
| Bereich | Anwendung | Beispiel |
|---|---|---|
| Gesundheitswesen | Pandemiebekämpfung | Verwendung von Big Data zur Nachverfolgung von COVID-19 Infektionsraten, Identifikation von Hotspots und Modellierung der Virusausbreitung zur effektiven Ressourcenzuteilung und Impfplanung. |
| Gesundheitswesen | Personalisierte Medizin | Einsatz von Big Data zur Anpassung medizinischer Behandlungen an individuelle Patientenprofile, basierend auf genetischen Informationen, Lebensstil und vorherigen Gesundheitsdaten. |
| Umweltschutz | Klimaforschung | Nutzung von Big Data zur Verbesserung von Klimamodellen und zum besseren Verständnis der Auswirkungen des Klimawandels durch Analyse von Satelliten- und Sensordaten. |
| Umweltschutz | Artenschutz | Anwendung von Big Data zur Überwachung von Wildtierpopulationen und deren Lebensräumen, mit Daten aus Drohnen, GPS-Trackern und anderen Quellen, die Einblicke in Wanderungsmuster und Populationsdynamiken bieten. |
| Verkehrswesen | Verkehrsmanagement | Big Data wird zur Analyse und Optimierung von Verkehrsströmen in Städten verwendet, was Staus reduziert, Reisezeiten verkürzt und den Kraftstoffverbrauch senkt. |
| Finanzwesen | Betrugserkennung | Einsatz von Big Data zur Erkennung von Mustern, die auf betrügerische Aktivitäten hinweisen, ermöglicht schnelle Identifikation und Reaktion auf ungewöhnliche Transaktionen. |
| Bildung | Lernanalytik | Verwendung von Big Data in Bildungseinrichtungen zur Analyse von Leistungsdaten und Verbesserung des Bildungserfolgs durch angepasste Lernmethoden und individuelle Lernpläne. |
In diesem Zusammenhang passt auch sehr gut dieses Zitat von Andrew McAffee, dem Direktor des MIT Sloan:
„The world is one big data problem.“
Big Data – Value, Variety, Velocity & Veracity
Die fortschreitende Integration und Analyse großer Datenmengen eröffnet neue Möglichkeiten zur Problemlösung und Innovation, fordert jedoch auch kontinuierliche Verbesserungen in der Datenverwaltung und -sicherheit.
Die vier V’s von Big Data – Volumen, Vielfalt, Geschwindigkeit und Wahrhaftigkeit – wurden ursprünglich von Gartner formuliert, um die Kerneigenschaften von Big Data zu beschreiben. Diese Definition hat sich im Laufe der Zeit um ein weiteres V erweitert, um die fortschreitende Entwicklung in diesem Bereich besser abzubilden.
- Volume (Volumen): Diese Dimension steht für das exponentiell wachsende Datenaufkommen, das Unternehmen speichern und analysieren müssen. Prognosen von Statista aus dem Jahr 2017 erwarten, dass sich das global jährlich erzeugte Datenvolumen bis zum Jahr 2025 auf 163 Zettabyte verzehnfachen wird.
- Variety (Vielfalt): Hiermit wird die Breite der Datenformate – strukturiert, semi-strukturiert und unstrukturiert – erfasst. Unstrukturierte Daten, die rund 90% des Datenvolumens ausmachen und meist aus Texten, Bildern oder Videos bestehen, sind in traditionellen relationalen Datenbanken schwer zu analysieren. Mit Hilfe von Big Data und Machine Learning können jedoch auch diese Daten effektiv ausgewertet werden.
- Velocity (Geschwindigkeit): Diese Dimension bezieht sich auf die Rate, mit der Daten produziert und verarbeitet werden müssen. In der heutigen Geschäftswelt ist die Fähigkeit zur Echtzeitverarbeitung entscheidend, da sie Unternehmen einen signifikanten Wettbewerbsvorteil verschaffen kann.
- Veracity (Wahrhaftigkeit): Diese Komponente betrifft die Genauigkeit und Verlässlichkeit der Daten. Oft erreichen Daten aus verschiedenen Quellen die Unternehmen in suboptimaler Qualität und erfordern eine aufwendige Nachbearbeitung, um nutzbar zu sein.
Die Definition wurde um zwei zusätzliche V’s erweitert:
- Value (Wert): Der wirtschaftliche Mehrwert, der durch die Analyse großer und verknüpfter Datenmengen erzeugt wird, vor allem durch den Einsatz von Machine Learning-Technologien. Der Wert ist ein zentrales Argument für Big Data-Initiativen, da ohne erkennbaren Nutzen solche Unterfangen keinen Sinn hätten.
- Validity (Validität): Die Qualität der Daten ist entscheidend für den Erfolg von Big Data-Projekten. Daten von schlechter Qualität können die Ergebnisse von Machine Learning-Modellen verzerren und im schlimmsten Fall zu falschen Vorhersagen führen.
Technologien hinter Big Data
Datenmanagement und -analysewerkzeuge
Datenmanagement-Systeme sind entscheidend für die Handhabung und Organisation großer Datenmengen. Zentrale Systeme wie Hadoop oder Datenverwaltungsplattformen wie Apache Cassandra ermöglichen es, Daten effizient zu speichern und zugänglich zu machen. Analysewerkzeuge wie Apache Spark und Qlik helfen, aus diesen großen Datenmengen wertvolle Erkenntnisse zu gewinnen:
- Hadoop dient der verteilten Speicherung und Verarbeitung großer Datenmengen.
- Apache Cassandra bietet robuste und skalierbare Datenverwaltung.
- Apache Spark ist für schnelle Analyse und Datenverarbeitung in Echtzeit bekannt.
- Qlik visualisiert Daten, um Trends und Muster leicht verständlich darzustellen.
Künstliche Intelligenz und Machine Learning
Der Einsatz von Künstlicher Intelligenz (KI) und Machine Learning ist zentral für die Weiterentwicklung von Big Data-Technologien. Plattformen wie TensorFlow und IBM Watson nutzen fortschrittliche Algorithmen, um Muster zu erkennen und Prognosen zu stellen, was die Entscheidungsfindung in Unternehmen wesentlich beeinflusst. Zusätzlich verstärken Large Language Models (LLMs) diese Technologien:
- TensorFlow wird vor allem für tiefgehendes Lernen in Bereichen wie Bild- und Spracherkennung eingesetzt.
- IBM Watson bietet robuste Analysetools für unstrukturierte Daten, einschließlich Sprach- und Textanalyse.
Large Language Models ergänzen diese Systeme durch Fähigkeiten in der Textverarbeitung und Analyse, automatisieren Kundeninteraktionen und unterstützen komplexe Entscheidungsprozesse. Durch die Kombination dieser Technologien können Unternehmen ihre Effizienz steigern und ihre Datenanalysekapazitäten erweitern.
Herausforderungen und Lösungen
In der Welt von Big Data stehen Organisationen und Unternehmen ständig vor Herausforderungen, die sowohl Datenschutz und Datensicherheit als auch die Komplexität der Datenintegration umfassen. Diese Herausforderungen erfordern innovative und effektive Lösungsansätze.
Datenschutz und Datensicherheit
Datenschutz und Datensicherheit haben höchste Priorität, da sie das Vertrauen der Nutzer sichern und gesetzlichen Anforderungen entsprechen müssen. Unternehmen stehen vor der Herausforderung, datenschutzrechtliche Bestimmungen zu beachten, die sich ständig weiterentwickeln.
MERKE:
- Regelkonforme Datenverarbeitung erfordert umfassendes Know-how in IT-Sicherheit.
- Verschlüsselungstechniken und sichere Datenspeicherungsmethoden sind notwendig, um Daten vor unbefugtem Zugriff zu schützen.
- Fortlaufendes Monitoring und regelmäßige Updates der Sicherheitsprotokolle tragen zur Risikominimierung bei.
Durch den Einsatz von fortschrittlichen Verschlüsselungstechnologien und die Implementierung von Access Control Systems können Unternehmen die Sicherheit sensibler Daten gewährleisten. Die Investition in Ausbildungsprogramme, die Mitarbeiter über Risiken und Sicherheitspraktiken informieren, ist ebenfalls entscheidend.
Komplexität der Datenintegration
Die Integration großer Datenmengen aus verschiedenen Quellen stellt eine weitere Herausforderung dar. Verschiedene Datenformate, Inkonsistenzen zwischen den Datenquellen und Zeitverzögerungen erfordern effiziente Lösungen zur Datenintegration.
- Nutzung von Middleware zur Vereinheitlichung der Datenintegration.
- Einsatz von ETL-Tools (Extract, Transform, Load), um Daten sicher und konsistent zu verarbeiten.
- Implementierung von Data Lakes für eine flexible und skalierbare Datenhaltung.
Ein effektives Datenintegrationsmanagement ermöglicht es Unternehmen, eine einheitliche Sicht auf ihre Daten zu erhalten und fundierte Entscheidungen zu treffen. Die Auswahl geeigneter Integrationswerkzeuge und -techniken, die eine automatisierte Verarbeitung und Echtzeitanalysen ermöglichen, ist dabei von zentraler Bedeutung.
| Herausforderung | Kernelemente |
|---|---|
| Datenschutz und Sicherheit | Verschlüsselung, Access Control, Schulungen |
| Komplexität der Integration | Middleware, ETL-Tools, Data Lakes |
Die Optimierung von Datenschutz und Datensicherheit sowie die Bewältigung der Komplexität der Datenintegration sind entscheidend für den effiziven Einsatz von Big Data. Durch den Einsatz moderner Technologien und ständige Fortbildungen können Unternehmen diese Herausforderungen erfolgreich meistern.
Zukünftige Trends bei Big Data
Big Data bleibt ein dynamischer Sektor, der sich ständig weiterentwickelt, um neuen Herausforderungen und Chancen Rechnung zu tragen. Die Technologien hinter Big Data erweitern sich um neue Innovationen, und die Auswirkungen auf verschiedene Industrien sind deutlich und weitreichend.
Innovationen in der Technologie
Die Welt der Big Data-Technologie ist geprägt von ständiger Innovation. Unternehmen, die sich auf die Entwicklung dieser Technologien spezialisieren, führen laufend neue Werkzeuge und Methoden ein, um mit den stetig wachsenden Datenmengen effizient umzugehen.
- Verbesserte Speicherlösungen: Entwicklungen im Bereich der Data Lakes und objektbasierte Speicherung helfen Unternehmen, große Datenmengen kostengünstig und skalierbar zu speichern.
- Beispiele: Amazon S3, Google Cloud Storage
- Fortgeschrittene Analytik: Neue Algorithmen und Machine Learning Modelle ermöglichen tiefere Einsichten und Vorhersagen.
- Beispiele: RAPIDS von NVIDIA, TensorFlow 2.0
- Automatisierung und Integration: Tools zur Datenintegration und automatisierten Datenverarbeitung werden verbessert, um den Arbeitsaufwand für Datenwissenschaftler zu reduzieren.
Passende Themen:


